Emukit: open source toolkit for statistical emulation and decision-making under uncertainty
Emukit is a highly adaptable Python toolkit for enriching decision-making under uncertainty. This is particularly pertinent to model complex systems where data is scarce or difficult to acquire. In these scenarios, propagating well-calibrated uncertainty estimates within a design loop or computational pipeline ensures that constrained resources are used effectively.
Some features of Emukit are:
-
Emukit separates models from decisions. Methods like Bayesian optimization, Bandits, Experimental design (active learning) or Bayesian quadrature can be jointly analyzed as Markov decision processes in some belief space. Emukit allows you to build such a belief space and to use it in several decision scenarios.
-
Emukit is agnostic to the underlying modelling framework. This means you can use any tool of your choice in the Python ecosystem to build the machine learning model and use it in a decision loop. Models written in GPy, TensorFlow, MXnet, etc. can easily be wrapped in Emukit and used in several sequential decision-making problems.
-
Emukit has been built using reusable components. Its main goal is to provide tools that ease the creation of new methods for uncertainty quantification and decision-making.
Main components of Emukit
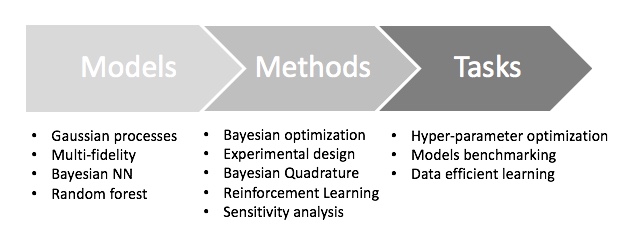
In a nutshell, decision-making methods implemented in Emukit are represented in the following high-level chart.

The main three component of methods implemented in Emukit are:
-
Models: probabilistic representation of the process/simulator that the user is working with. Although multi-fidelity models are offered in Emukit, there is normally a modelling framework that is used to create the model. Examples are Bayesian neural networks, Gaussian process or random forest.
-
Methods: low-level techniques that are aimed to understanding, quantifying or using uncertainty that the model provides. Examples are Bayesian optimization or experimental design.
-
Tasks: high level questions that the owners of the target process/simulator are interested on. Examples are understanding the propagation of uncertainty in a simulator, explain a complex system behavior or calibrate a simulator.
Build your model, run your method, solve your task
The typical workflow that we envision for a user interested in using Emukit is:
- Figure out which questions/tasks are important for in regard to their process/simulation.
- Understand which emulation techniques are needed to accomplish the chosen task.
- Build an emulator of the process. That can be a very involved step, that may include a lot of fine tuning and validation.
- Feed the emulator to the chosen technique and use it to answer the question/complete the task.
The following workflow summarizes this steps and the techniques currently implemented in Emukit.
Build your model
Generally speaking, Emukit does not provide modelling capabilities, instead expecting users to bring their own models. Because of the variety of modelling frameworks out there, Emukit does not mandate or make any assumptions about a particular modelling technique or a library. Instead it suggests to implement a subset of defined model interfaces required to use a particular method. Nevertheless, there are a few model-related functionalities in Emukit:
- Example models, which give users something to play with to explore Emukit.
- Model wrappers, which are designed to help adapt models in particular modelling frameworks to Emukit interfaces.
- Multi-fidelity models, implemented based on GPy.
Run your method
This is the component and focus of Emukit. Emukit defines a general structure of a decision-making method, called OuterLoop, and then offers implementations of several such methods: Bayesian optimization, sensitivity analysis, Bayesian quadrature and experimental design. All methods in Emukit are model-agnostic and defining new APIs to accommodate other frameworks is easy.
The main features currently available in Emukit are:
- Bayesian optimization: optimize physical experiments and tune parameters of machine learning algorithms;
- Experimental design/Active learning: design the most informative experiments and perform active learning with machine learning models;
- Sensitivity analysis: analyze the influence of inputs on the outputs of a given system;
- Bayesian quadrature: efficiently compute the integrals of functions that are expensive to evaluate;
- Benchmarking: a benchmarking tool with some functionalities is available for some of the methods.
Solve your task
Check this folder for examples of things people did with Emukit. Additionally, we have integrated in the core part of the library a simple benchmarking tool to compare different Bayesian optimization methods.
Get started!
If you want to start using Emukit just have a look to the different examples in the landing page or have a look at the tutorials.